

“Antiyanks” is back at it again and has switched tactics to spamming a massive number of comments in a short period of time. In addition to being annoying (and sad and pathetic), it’s having a deleterious effect on performance and drowns out any discussions happening in those posts. That spam also federates as well as the eventual removals, so it’s not limited to just the posts being targeted.
Looking at the site config for the home instance of the latest two three alts, the rate limits were all 99999999. 🤦♂️
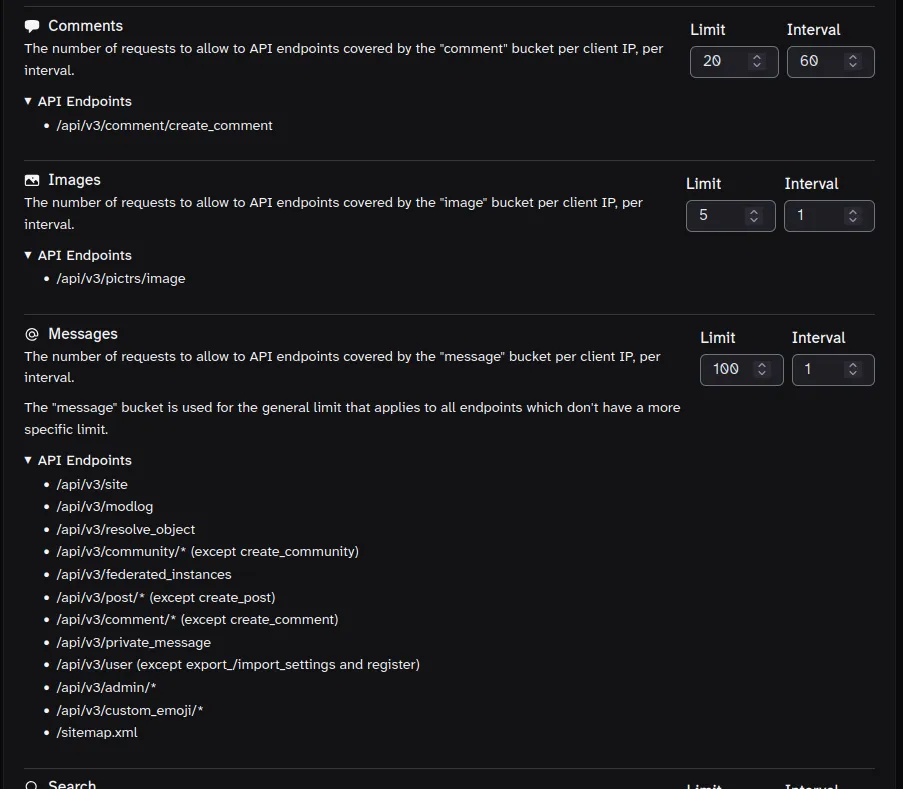
Rate limits are a bit confusing, but they mean: X number of requests per Y seconds per IP address.
The comment API endpoint has its own, dedicated bucket. I don’t recall the defaults, but they’re probably higher than you need unless you’re catering to VPN users who would share an IP.
Assuming your server config is correctly passing the client IP via the XFF header, 20 calls to the /create_comment endpoint per minute (60 seconds) per client IP should be sufficient for most cases, though feel free to adjust to your specific requirements.
Edit: A couple of instances accidentally set the “Messages” bucket too low. That bucket is a bit of a catch-all for API endpoints that don’t fit a more specific bucket. You’ll want to leave that one relatively high compared to the rest. It’s named “Messages” but it covers far more than just DMs.
https://nginx.org/en/docs/http/ngx_http_proxy_module.html
$proxy_add_x_forwarded_foris a built-in variable that either adds to the existing X-Forwarded-For header, if present, or adds the XFF header with the value of the built-in$remote_ipvariable.The former case would be when Nginx is behind another reverse proxy, and the latter case when Nginx is exposed directly to the client.
Assuming this Nginx is exposed directly to the clients, maybe try changing the bottom section like this to use the
$remote_addrvalue for the XFF header. The commented one is just to make rolling back easier. Nginx will need to be reloaded after making the change, naturally.Thanks!
I was able to crash the instance for a few minutes, but I think I have a better idea of where the problem is. Ths $emote_addr variable seems to work just the same.
In the rate limit options there is a limit for ‘‘Message’’. Common sense tells me that this means ‘direct message’, but setting this to a low number is quite bad. While testing I eventually set it to ‘1 per minute’ and the instance became unresponsive until I modified the settings in the database manually. If I give a high number to this setting then I can adjust the other settings without problem.
“Message” bucket is kind of a general purpose bucket that covers a lot of different endpoints. I had to ask the lemmy devs what they were back when I was adding a config section in Tesseract for the rate limits.
These may be a little out of date, but I believe they’re still largely correct:
So, ultimately my problem was that I was trying to set all of the limits to what I thought were “reasonable” values simultaneously, and misunderstood what ‘Message’ meant, and so I ended up breaking things with my changes without the reason being obvious to me. I looked into the source code and I can see now that indeed ‘Messages’ refer to API calls and not direct messages, and that there is no ‘Direct Message’ rate limit.
If I let ‘Messages’ stay high I can adjust the other values to reasonable values and everything works fine.
Thanks a lot for your help!! I am surprised and happy it actually worked out and I understand a little more 😁
Hi I think I set the messages too low as well and now no.lastname.nz is down, pointers on how to fix with no frontend?
Sorry, I went to sleep. Glad you were able to sort it out 😄
All good, taught me again not to rely on chatGPT. I even said I needed to find the right BD table and field and it lead me down a rabbit hole of editing config/env files
Fuck AI
Haha, yeah, trusting ChatGPT with how to manipulate the database and change config files is a risky move 😆 I did use it myself to remind me of the postgresql syntax to find and alter the field.
If you have DB access, the values are in the
local_site_rate_limittable. You’ll probably have to restart Lemmy’s API container to pick up any changes if you edit the values in the DB.100 per second is what I had in my configuration, but you may bump that up to 250 or more if your instance is larger.
Thanks:
UPDATE local_site_rate_limit SET message = 999, message_per_second = 999 WHERE local_site_id = 1;Awesome! Win-win.
😁 👍