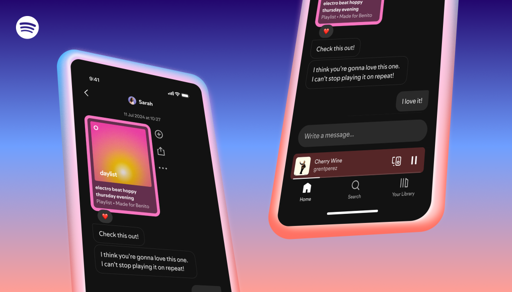
Recommendations have always been at the heart of the Spotify experience. Friends and family share their favorite music, podcasts, audiobooks, and more from Spotify millions of times each month. That’s because word of mouth is one of the most powerful ways for people to discover their next favorite track. Spotify users have told us they...
Which they can sell to advertisers LLM and AI companies.
It’s not talked about too much, because it is not in the best interest of the stockholders. But AI as it was popularized by openAI and both images and text generators already reached a boundary of data availability. There’s no more human made data. They are now resorting to synthetic data, which is to make one first generation LLM model create tons of data to train newer or more tailored weighs models. With the issue that this new models develop problems from inbreeding of the data. Training models on other genAI products poisons the models and corrupts their generative power in just a few generations. This is why genAI images are increasingly turning yellow, the same reason newer models are more fragile and hallucinate or go psychotic more easily than old models. So, the AI companies need new sources of human made data to mix in with the synthetic data.
The main problem is that we ran out, there’s no more data made by humans to train AI with. Humans don’t create new data fast enough to train all the new models with the new doodads and features the AI companies want to sell. So now these companies will pay anything just to get their hands on new fresh stuff. These is why any app in the planet will now pivot to do anything they can to get chats going. It’s a new source of data to sell to data brokers.
Barf. I try hard not to think about it, since it’s shoved in our faces at every turn, but you’re absolutely right that our data is going to these AI corpos.


It’s not talked about too much, because it is not in the best interest of the stockholders. But AI as it was popularized by openAI and both images and text generators already reached a boundary of data availability. There’s no more human made data. They are now resorting to synthetic data, which is to make one first generation LLM model create tons of data to train newer or more tailored weighs models. With the issue that this new models develop problems from inbreeding of the data. Training models on other genAI products poisons the models and corrupts their generative power in just a few generations. This is why genAI images are increasingly turning yellow, the same reason newer models are more fragile and hallucinate or go psychotic more easily than old models. So, the AI companies need new sources of human made data to mix in with the synthetic data.
The main problem is that we ran out, there’s no more data made by humans to train AI with. Humans don’t create new data fast enough to train all the new models with the new doodads and features the AI companies want to sell. So now these companies will pay anything just to get their hands on new fresh stuff. These is why any app in the planet will now pivot to do anything they can to get chats going. It’s a new source of data to sell to data brokers.
Barf. I try hard not to think about it, since it’s shoved in our faces at every turn, but you’re absolutely right that our data is going to these AI corpos.